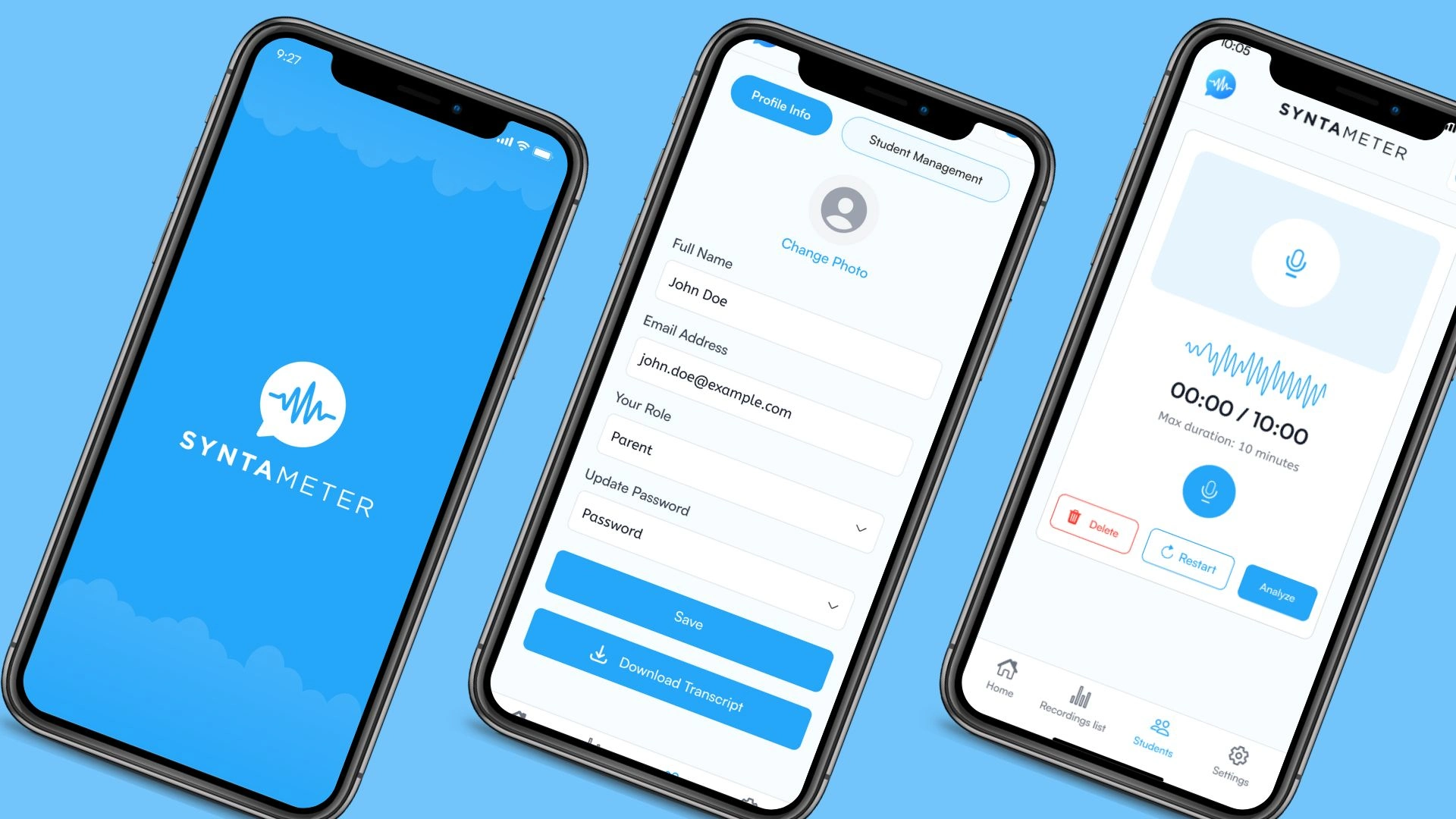
Executive Summary
Language assessment is painstaking, expert-level work. Transcribing a child’s speech sample, segmenting it into utterances, classifying sentence structures, computing standardized metrics, assembling a shareable report — each step demands trained attention. Done manually, the full process takes hours. It varies between scorers. It delays the clinical and instructional decisions that depend on it.
Syntameter was built to change that. Their vision was an AI agent platform that could analyze children’s speech and writing samples, classify sentence structures, compute standardized language metrics, and return a complete, shareable report — automatically, consistently, and fast.
Aegasis Labs built that system as a multi-agent AI platform: seven specialized agents, each owning a discrete stage of the assessment process, working in sequence to carry every sample from raw input to final, annotated report — without human intervention at any step in between.
The platform launched in production. Real teachers. Real clinics. Real research studies. Assessment processing time dropped by approximately 85%. Full reports now complete in under 90 seconds. In the first rollout, 80% of teachers ran assessments weekly — a frequency that was operationally impossible before.
About Syntameter
Syntameter is an education-focused startup building tools to understand and measure how children develop language. Their users span classrooms, therapy clinics, and research programs — teachers tracking grammar development across a class, speech-language therapists monitoring individual progress, researchers running IRB-approved studies, and parents who want to understand how their child is doing.
What every one of those users shares is the same underlying frustration: the existing process doesn’t scale.
Manual transcription and hand-scoring of speech or writing samples is the current standard across the field. It works. But it’s slow, labor-intensive, and prone to scorer variability — and that variability is a serious problem when you’re trying to measure growth over time or compare outcomes across a study cohort. Two trained professionals applying the same rubric to the same sample will sometimes reach different conclusions. For research, that’s a methodological flaw. For classroom use, it means assessments that should happen weekly happen monthly, if at all.
Syntameter’s founding team came from education and language research. They knew the problem with precision. What they needed was a technical partner capable of translating a well-defined research vision into a reliable, deployable product — one that met the accuracy standards of the research lab and the usability requirements of the classroom.
The Challenge
Precision Work That Doesn’t Scale
Three constraints defined the scope from the start. Each one was non-negotiable.
Speed and accuracy had to move together. Automating the process only creates value if the automated output is trustworthy. A fast pipeline producing unreliable classifications doesn’t replace manual scoring — it just produces wrong numbers faster. The system had to be both.
Multilingual support wasn’t optional. A significant portion of the student populations Syntameter serves speak English, Spanish, or Mandarin/Cantonese at home. Most existing tools are built for a single language and break down with mixed or non-English input. Syntameter needed consistent, language-aware performance across all three from day one.
Research-grade compliance was a design requirement, not a checklist. Schools and universities running IRB-approved studies have strict obligations around consent, data handling, and audit trails. Any platform serving that use case had to be built for compliance from the first line of architecture — not retrofitted later.
Beneath all three sat a product design challenge that mattered just as much: the people using this platform daily are teachers and speech therapists, not engineers. A technically sound system that’s awkward to use in a classroom doesn’t get used. The interface had to be as deliberately considered as the AI architecture behind it.
The Solution
A Multi-Agent AI Platform for Language Assessment
Aegasis Labs designed and built Syntameter as a multi-agent AI platform — a coordinated system of seven specialized agents, each responsible for a single, well-defined stage of the assessment workflow. No agent does everything. Each agent does its job precisely, then hands the result to the next.
The human submits a sample. The agents do the rest.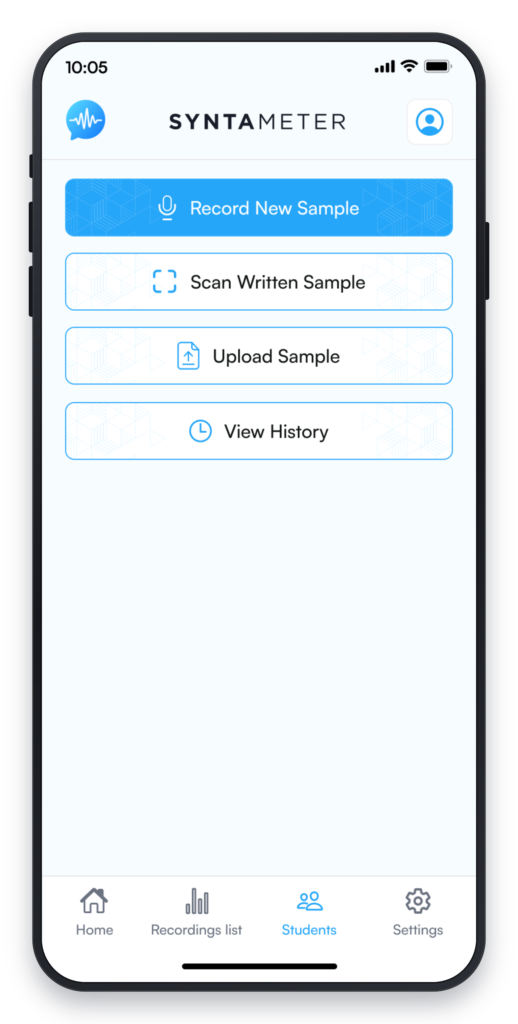
The Agent Architecture
Agent 1 — Ingestion Agent The entry point for every assessment. Receives the incoming sample — live speech recorded in the app, uploaded audio, or a written sample as an image or PDF — validates the input, detects the language, and routes it to the correct downstream processing pipeline. This is the agent that decides whether the Transcription Agent receives an audio stream or a document.
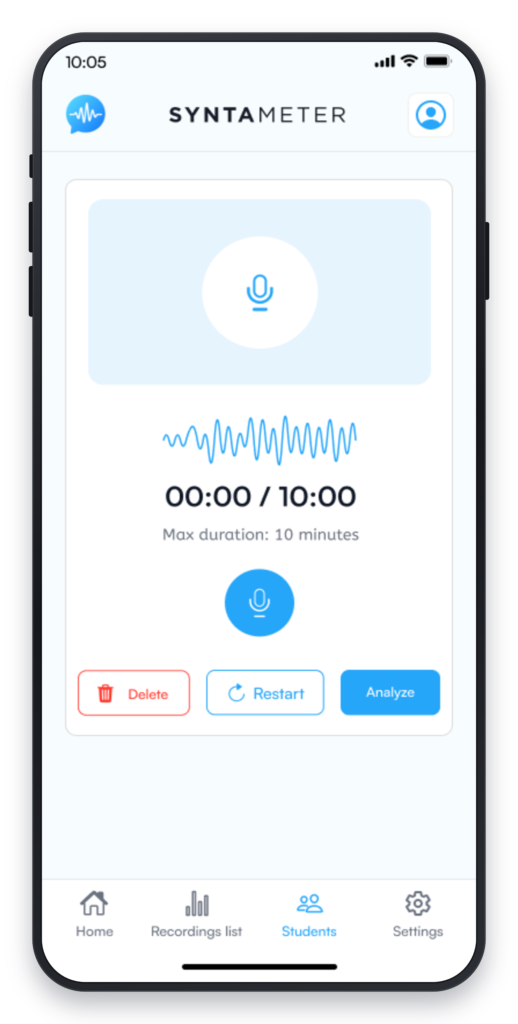
Agent 2 — Transcription Agent Handles the conversion of raw input into clean, analyzable text. For speech samples, this agent runs ASR (automatic speech recognition) tuned for child speech patterns, with processing adapted to the detected language. For written samples, it runs OCR to extract clean text from images or PDFs. Output: a raw transcript, correctly attributed, ready for segmentation. Accuracy: ~95% on OCR, >90% utterance segmentation across all three supported languages.
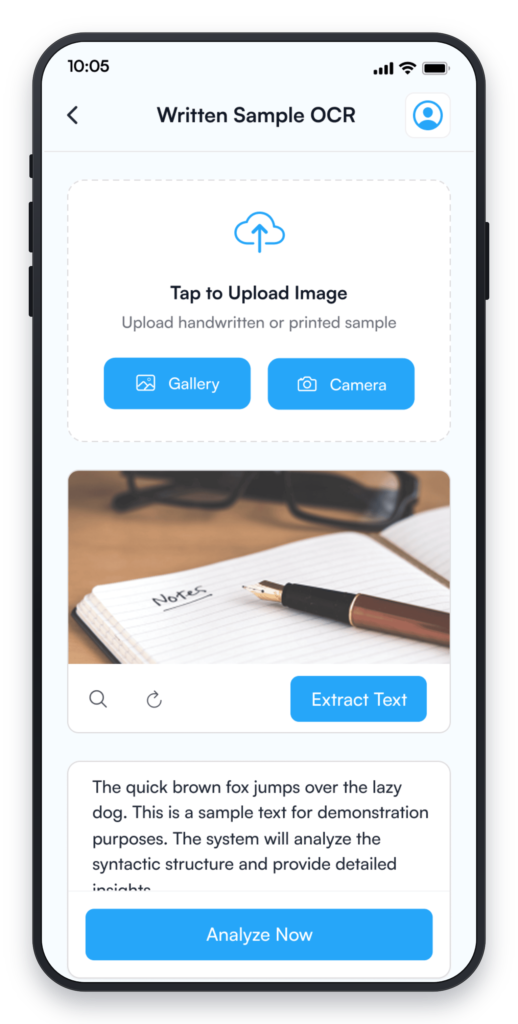
Agent 3 — Segmentation Agent Splits the raw transcript into discrete, linguistically meaningful utterances. Uses pause detection for speech-derived transcripts, punctuation rules for written input, and custom logic tuned specifically for child language patterns and multilingual edge cases. This agent’s output — clean, segmented utterances — is what every downstream analysis step depends on. Getting segmentation wrong cascades through everything that follows.
Agent 4 — Linguistic Analysis Agent The core NLP engine. Runs spaCy-based dependency parsing with custom rule logic for clause boundaries, subordinating conjunctions, and subordinate structures — and classifies each utterance as Simple, Compound, Complex, or Compound-Complex. This agent applies the same classification rules to every sample, every time. No scorer variability. No interpretation differences between assessors. Consistent labels, reproducibly.
Agent 5 — Scoring Agent Takes the classified utterances and computes the standardized metrics that educators and researchers already rely on: Variability (Shannon-index-based), Quality, Non-Repetitious Mean Length of Utterance (MLU), and a Composite score. The mathematical models are reproducible and comparable across sites, studies, and time points — which is precisely what research-grade assessment requires.
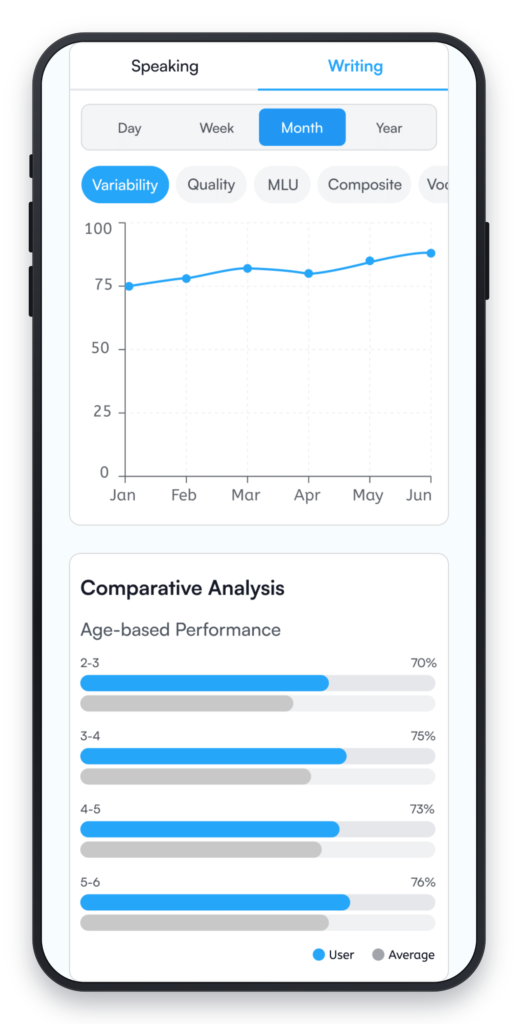
Agent 6 — Reporting Agent Assembles the final output. Generates annotated transcripts with morpheme counts, lexical inventory, sentence-type tags, and confidence indicators. Builds interactive progress dashboards showing individual growth trajectories, class-level views, benchmark comparisons, and intervention flags. Packages reports for one-click sharing with parents. The complete, ready-to-read report — from intake to delivery — lands in under 90 seconds.
Agent 7 — Compliance Agent Runs in parallel throughout the pipeline. Manages consent flows, enforces role-based access permissions for teachers, researchers, and parents, maintains auditable sharing histories, and ensures encrypted storage of all student data. For IRB-approved research studies, this agent provides the end-to-end compliance infrastructure those engagements require — built into the architecture, not bolted on afterward.
What Was Built
The platform is a production system, not a prototype. Every component was engineered to perform under real classroom and clinical conditions.
- Multi-language speech and text intake — Live recording, audio upload, image and PDF upload. All inputs processed consistently across English, Spanish, and Mandarin/Cantonese.
- Utterance segmentation engine — Linguistically grounded, tuned for child speech, handles multilingual edge cases.
- Sentence-type classification — spaCy dependency parsing with custom rule logic for clause boundaries and subordination. Consistent Simple / Compound / Complex / Compound-Complex labels at utterance level.
- Standardized scoring engine — Reproducible computation of Variability, Quality, Non-Repetitious MLU, and Composite metrics using mathematical models that are comparable across sites and time points.
- Annotated transcripts — Auto-generated with morpheme counts, lexical inventory, sentence-type tags, and confidence indicators, structured for both classroom and research export.
- Progress dashboards — Interactive visualizations (D3.js, Chart.js) with individual growth trajectories, class-level and district-level views, benchmark comparisons, and intervention flags.
- IRB-compliant data handling — Consent flows, auditable permissions, role-based access, encrypted storage. Built to meet research ethics requirements from the first architectural decision.
- Scalable cloud backend — AWS Lambda for elastic execution, S3 for encrypted storage, event-driven processing for ASR/OCR and NLP jobs, CloudWatch monitoring, automated daily backups.
- Teacher-friendly React frontend — Built around real classroom workflows. Quick recording and upload, one-click report sharing, accessible progress visualizations that parents can actually read.
Aegasis Labs designed and built Syntameter from the ground up — UI/UX, data architecture, NLP engines, scoring models, and cloud deployment. The goal was to remove every manual step from the assessment workflow without removing any of the rigor.
The platform accepts two types of input: live speech recorded directly in the app, and written samples uploaded as images or PDFs. From there, the pipeline takes over.
Technologies The platform was built on a modern, production-grade stack selected for reliability at scale:
- Languages & Frameworks: Python, FastAPI, Flask, React
- NLP & AI: spaCy, custom syntactic scoring models, ASR/OCR integrations
- Database: PostgreSQL
- Cloud: AWS Lambda, S3, SAM, CloudWatch
- Testing & CI/CD: Pytest, automated pipelines
- Visualization: D3.js, Chart.js
- Security & Compliance: IRB consent management, encrypted storage
The Results
Syntameter launched as a production platform used by real teachers, therapists, and researchers — not a pilot or a proof of concept. The outcomes it delivered against the core problems it was built to solve are concrete and sourced directly from rollout data.
- Fast assessments: Assessment processing time dropped by approximately 85%. What previously required manual transcription and hand-scoring — a process measured in hours — now completes in under 90 seconds. That shift doesn’t just save time. It changes what’s operationally possible: weekly assessments become realistic where monthly ones were already a stretch.
- High accuracy: ~95% OCR accuracy and >90% ASR-based utterance segmentation across English, Spanish, and Mandarin/Cantonese. Those numbers matter because the platform’s value depends entirely on whether educators and researchers can trust the scores it produces.
- Proven adoption: 80% of teachers ran weekly assessments in the first rollout.
- Parent engagement: 60% of parents opened shared reports within 24 hours.
- Research-grade compliance: End-to-end IRB-compliant workflows with consent tracking and an auditable history.
- Rich, actionable insights: Automatic transcripts with sentence types, morpheme counts, lexical inventory, and clear Variability/Quality/MLU/Composite scores.
- Live dashboards: Real-time progress views for classrooms and districts, with benchmarks and flags for students who may need intervention.
- Multilingual by design: Supports English, Spanish, and Mandarin/Cantonese for both speech and text samples.
- Scalable and reliable: Cloud-native architecture (AWS Lambda + S3) handles thousands of samples with automated backups and monitoring.
- Secure data handling: Encrypted storage, least-privilege access, and daily backups to protect sensitive student information.
Why the Agentic Architecture Mattered
A monolithic automated tool might have handled the transcription. Or the scoring. Probably not both, reliably, across three languages, at research-grade accuracy.
The agentic architecture worked because it decomposed a hard, multi-domain problem into discrete, testable, improvable stages. When OCR accuracy needed tuning, the Transcription Agent could be refined without touching the Scoring Agent. When compliance requirements evolved, the Compliance Agent could be updated independently. Each agent owns its scope. Each agent can be evaluated, tested, and improved in isolation.
That modularity is also why the platform scales. Adding a new language, a new assessment metric, or a new output format means adding or extending an agent — not rebuilding the system.
Build Your AI Product with Aegasis Labs
Syntameter came to us with a research-grounded vision, a technically demanding domain, and users — teachers, therapists, parents — who needed the product to work simply and reliably in their daily routines. That combination requires more than engineering competence. It requires understanding how to translate domain expertise into AI behavior that holds up under real-world conditions.
That combination demands more than engineering competence. It requires understanding how to decompose complex domain expertise into AI behavior that holds up under real-world conditions, then architecting a system where specialized agents carry that behavior reliably, at scale, across every assessment.
Ready to Build? If you’re building an intelligent system that needs to perform accurately in a high-stakes domain, visit aegasislabs.com to start the conversation.