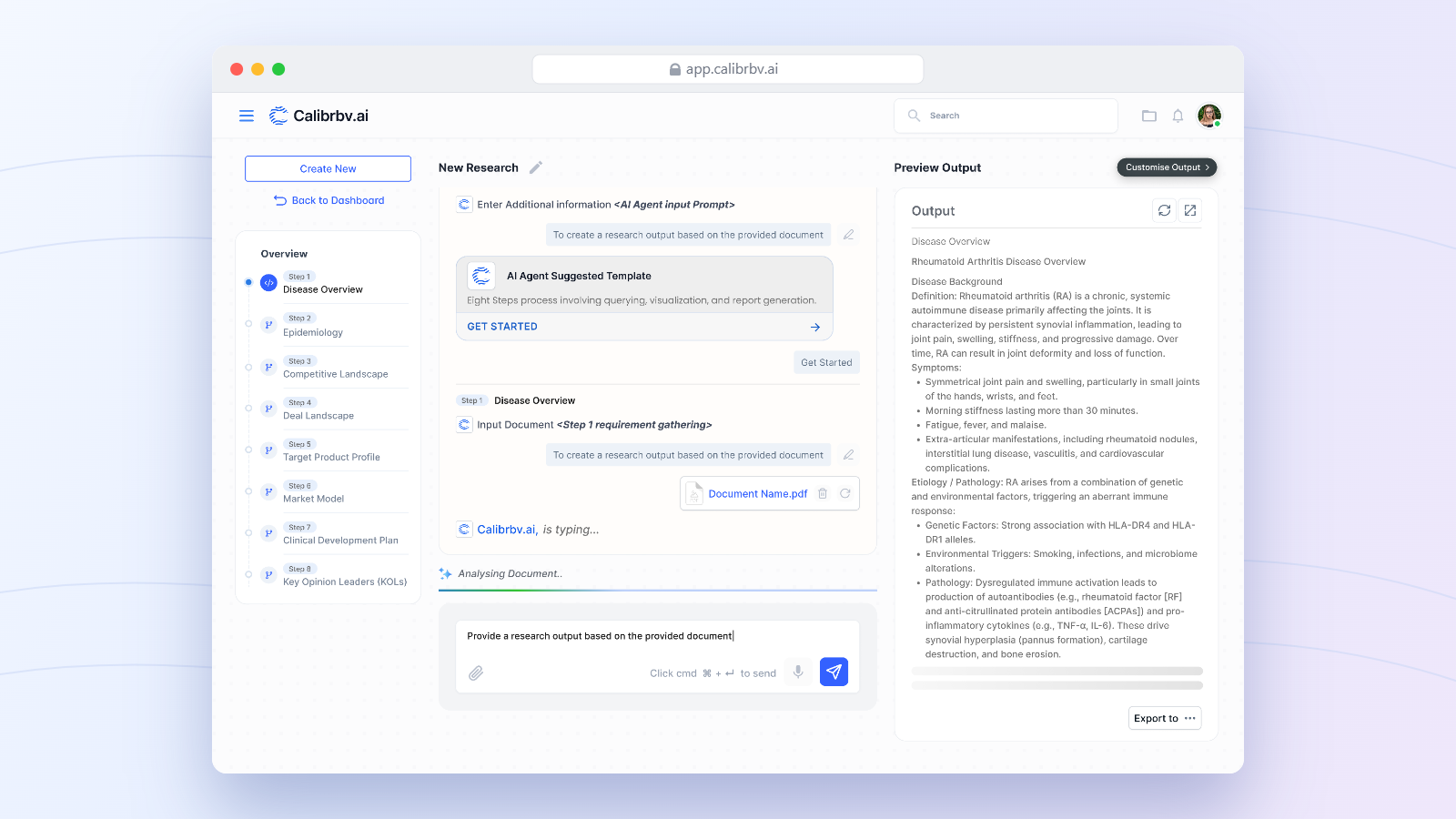
Executive Summary
Biomedical research moves at the speed of data. But for most research teams, data does not move. It sits scattered across APIs, proprietary spreadsheets, clinical trial databases, and public repositories, waiting for someone to manually pull it together. That someone is usually a researcher. The hours they spend gathering and cross-referencing information are hours not spent on the scientific work only they can do.
Scripps Research needed that bottleneck eliminated. They came to Aegasis Labs with a clear brief: build an intelligent research assistant capable of autonomously handling the entire data gathering and synthesis workflow across multiple structured and unstructured sources, and delivering cited, human-readable research outputs that scientists could act on immediately.
We built CalibrBV, a modular, multi-agent AI research platform that decomposes complex biomedical queries, retrieves data from live APIs, proprietary spreadsheets, and public research sources simultaneously, synthesizes findings across all of them, and returns contextual, citation-backed reports in a conversational interface. The result was a reduction in manual data collection and synthesis time of over 70 percent, and a research environment where scientists spend their time on interpretation and innovation rather than information retrieval.
About the Client
Scripps Research is one of the most influential nonprofit biomedical research institutes in the world. Founded in 1924 and headquartered in La Jolla, California, the institute has spent a century building a reputation for scientific excellence in the life sciences and chemistry, training generations of the scientific leaders who now shape the field.
The scale of the operation reflects that reputation. Scripps Research runs more than 170 laboratories and employs over 2,100 scientists, technicians, graduate students, and administrative staff, with research spanning an interdisciplinary range of biomedical disciplines. That breadth is exactly what makes the institute’s data environment so demanding. Researchers across drug development, clinical trials, company analysis, and regulatory filings all depend on the quality and speed of evidence gathering to drive the quality and speed of scientific outcomes.
Relevant information for any given research question lives across GlobalData APIs covering drugs, trials, deals, companies, and filings, proprietary Citeline spreadsheets holding structured clinical and market data, and the broader public research landscape accessible through open-source tools and literature databases. Each source has different formats, different access methods, and different levels of structure.
Getting a complete picture of any research question required navigating all of them manually, sequentially, and with significant time investment before any actual analysis could begin. An institute operating at this scale, with this many active research threads, needed a platform that could do that work autonomously, accurately, and at speed. CalibrBV was the answer.
The Challenge
Fragmented Data. Repetitive Work. Slower Science.
Biomedical research has a data problem that does not get talked about enough. It is not the problem of too little data. It is the problem of too much friction in accessing it.
A researcher pursuing a hypothesis about a drug compound’s clinical trial landscape might need to query GlobalData for active trials, cross-reference Citeline spreadsheet data on related compounds, scan recent literature for relevant findings, and pull company filing information to understand the commercial context. Each of those steps requires a different tool, a different interface, and a different mental context switch. Done manually, a thorough research synthesis on a single query can consume a significant portion of a working day before any actual scientific thinking has begun.
Scripps Research needed a system that could handle the entire retrieval and synthesis workflow autonomously, across all relevant sources, simultaneously, and return outputs that were not just fast but traceable. Researchers needed to trust the outputs, which meant every insight had to come with its source. A system that produced confident-sounding summaries without clear attribution would be worse than useless in a scientific context.
The technical challenge was substantial. Building an agent that could decompose an open-ended biomedical research prompt into discrete retrieval tasks, route those tasks to the right data sources, maintain reasoning consistency across a multi-step workflow, and synthesize coherent findings across structured APIs, spreadsheet data, and unstructured web content, all while managing session state and returning results through a clean research interface, required architectural sophistication well beyond a simple API wrapper.
The Solution
A Multi-Agent Research Platform Built for Biomedical Complexity
Aegasis Labs designed and built CalibrBV as a modular, multi-agent AI system, architected specifically for the complexity of multi-source biomedical research. Every component was designed around two requirements that do not always coexist comfortably: speed and traceability. Fast results that researchers cannot verify are a liability. Traceable results that take too long to generate do not get used. CalibrBV delivers both.
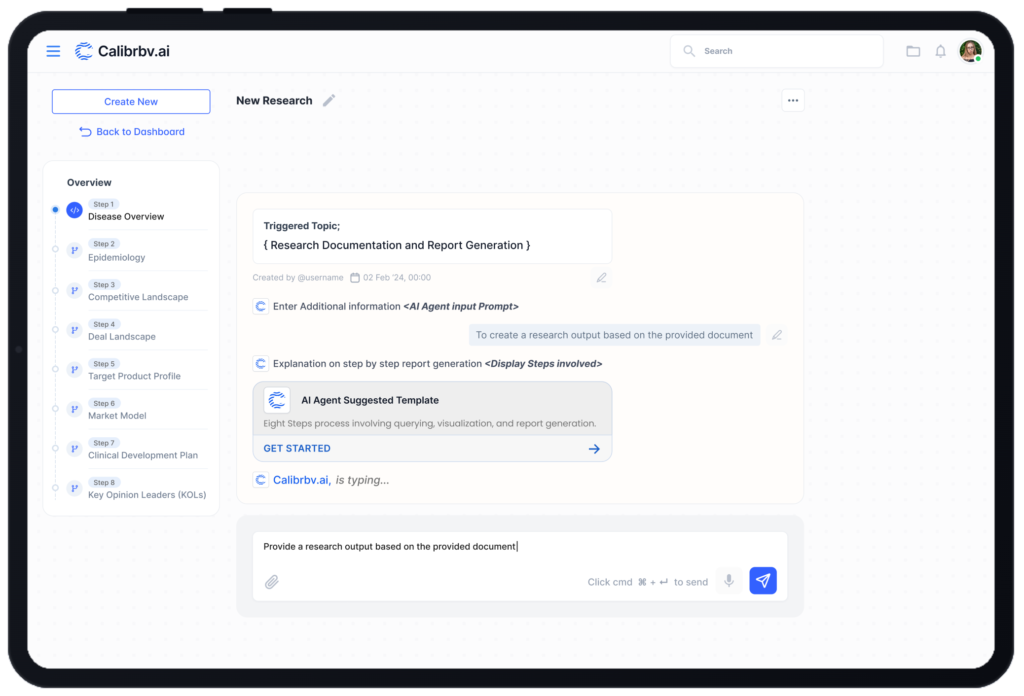
Supervisor Agent — Orchestrating the Research Workflow
At the top of the architecture sits a Supervisor Agent responsible for decomposing complex research prompts into granular, routable tasks. When a researcher submits a query, anything from a targeted drug pipeline question to a broad competitive landscape analysis, the Supervisor breaks it into discrete sub-tasks, determines which data sources are relevant to each, and routes them to the appropriate agents in parallel.
This orchestration layer maintains stateful, multi-step reasoning consistency across the entire workflow. Tasks do not execute in isolation. The Supervisor ensures that intermediate findings inform downstream retrieval and that the final synthesis reflects the full research picture, not just the last query result.
Custom Research Agent — Multi-Source Retrieval and Synthesis
The Research Agent handles the actual data work. It connects to GlobalData APIs covering drugs, clinical trials, deals, companies, and filings, pulls structured insights from Citeline spreadsheets using Pandas-based parsing, and accesses public research sources through a GPT Researcher powered layer for open literature and web data.
Critically, the agent does not just retrieve data. It classifies task intent, retrieves relevant content, and synthesizes results with contextual references before returning output to the Supervisor. Model Context Protocol is implemented throughout to enrich research context and ensure data traceability. Every finding comes with its source. Researchers know not just what the system found, but where it came from.
The underlying reasoning layer uses a React-based design for reasoning and action chaining, allowing the agent to make intermediate inferences, adjust retrieval based on partial findings, and handle the kind of multi-step reasoning that complex biomedical queries require.
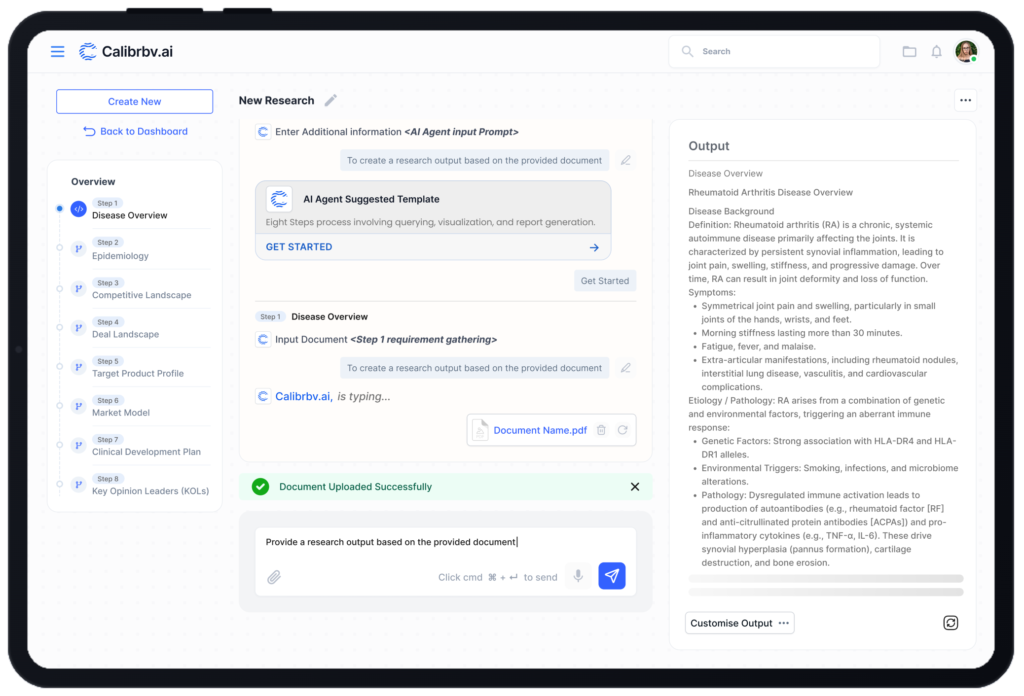
FastAPI Backend — Orchestration Hub
The backend is built on FastAPI, serving as the central orchestration hub managing user sessions, API requests, and research flows end to end. Endpoints handle task submission, result retrieval, and structured research summaries. Redis manages session state and task caching, maintaining conversational context across multi-step research flows and improving responsiveness for iterative queries.
The Web Research Agent — Open-Source Intelligence
For queries that extend beyond proprietary datasets into the broader scientific literature and public biomedical resources, this agent deploys a GPT Researcher powered layer for open-source data exploration. It retrieves, reads, and summarizes relevant public findings, adding the breadth of published research to the depth of structured proprietary data.
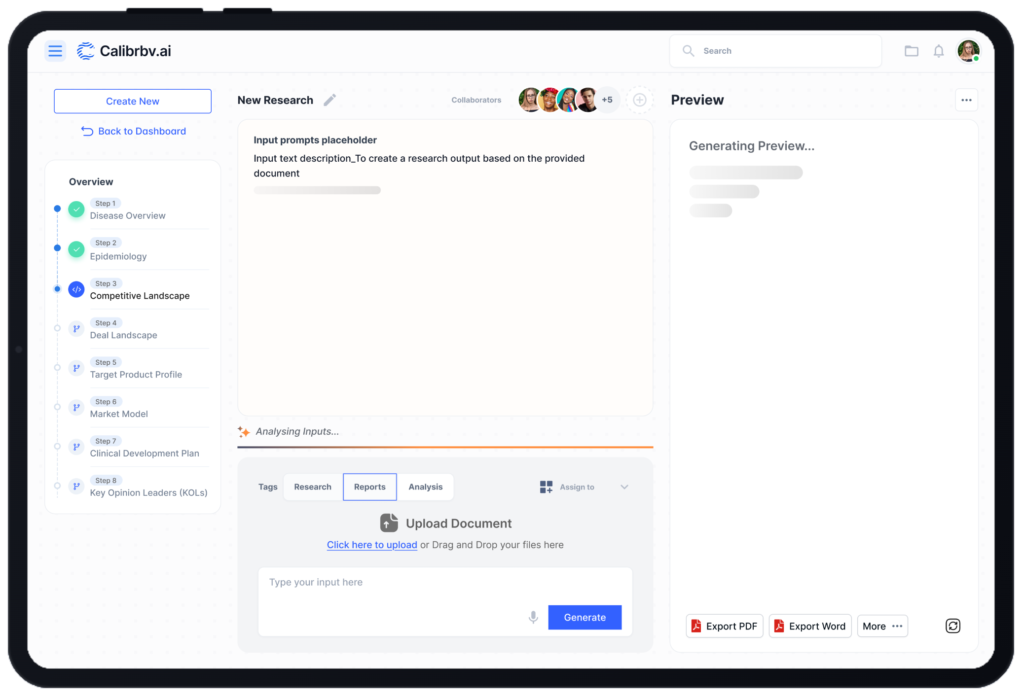
The Synthesis Agent — Multi-Source Report Assembly
This is the output layer. Once the Supervisor confirms that all subtask results are complete, the Synthesis Agent aggregates findings from all active research agents, resolves conflicts or gaps in the data, and generates a structured, human-readable research summary. Reports include contextual references, citation-level traceability for each claim, and scientific language calibrated to the domain. This is the agent that turns raw multi-source data into something a researcher can act on immediately.
GPT-4 for Biomedical Reasoning and Generation
The ML layer is powered by OpenAI GPT-4, integrated with custom prompting pipelines tailored for biomedical reasoning, language generation, and synthesis. The system does not apply a general-purpose language model to a specialized domain without adaptation. The prompting architecture was designed specifically for scientific context, ensuring that summaries are accurate, appropriately hedged, and grounded in the retrieved source material rather than model priors.
React Frontend: A Research Interface Researchers Actually Use
The front end was built in React, giving researchers a clean, chat-like interface for submitting prompts, tracking multi-step task progress, and viewing generated reports. Real-time updates from the FastAPI backend mean researchers see progress as it happens rather than waiting for a completed batch output.
Session and State Management: Redis-Backed Continuity
This layer manages conversational state across multi-step research flows. Researchers can iterate on a query, drill deeper into a finding, or pick up a research thread across sessions without losing context. Redis caching also improves platform responsiveness under concurrent research loads, keeping the experience fluid even when the underlying orchestration is processing multiple parallel subtasks.
What Was Built
The platform is a production research environment, engineered for real scientific workloads.
- Supervisor-led multi-agent orchestration — Multi-Agent (Supervisor, Research, Spreadsheet, Web Research, and Synthesis Agents, React-based)
- GlobalData API integration — Real-time access to structured datasets across Drugs, Trials, Deals, Companies, and Filings. Intent-classified queries with contextual output.
- Citeline spreadsheet intelligence — Pandas-based parsing of CSV and XLSX files for structured insight extraction from proprietary institutional datasets.
- GPT Researcher-powered web layer — Open-source biomedical literature retrieval and summarization, integrated into the multi-agent synthesis pipeline.
- Multi-source synthesis engine — GPT-4-powered aggregation of structured API data, spreadsheet findings, and public literature into coherent, citation-backed research reports.
- Model Context Protocol (MCP) traceability — End-to-end source provenance for every claim in every report. Scientific auditability by design.
- FastAPI backend — Orchestration hub managing user sessions, API requests, and research flows. Endpoints for task submission, result retrieval, and structured summaries.
- Redis session management — Stateful multi-step research flows with caching for responsiveness under concurrent load.
- React frontend — Chat-like research interface for prompt submission, multi-step task tracking, and report viewing. Real-time updates via FastAPI integration.
Technologies
- FastAPI
- Redis
- React
- Python
- Pandas
- OpenAI GPT-4, GPT Researcher, Model Context Protocol (MCP),
- GlobalData API
- Citeline Spreadsheets, HTTP Clients
How We Work
The CalibrBV engagement followed Aegasis Labs‘ four-step delivery approach, designed to translate a complex technical brief into a production system without losing scientific precision along the way:
- Discover — We worked closely with the Scripps Research team to map the full research workflow, understand the data sources in play, and define the accuracy and traceability requirements that would determine whether the system was genuinely useful in practice.
- Design — We architected the multi-agent system, including Supervisor orchestration, Research Agent retrieval, Model Context Protocol traceability, and the frontend interface, as a coherent blueprint before any production code was written.
- Build — Our team delivered across the full stack: FastAPI backend, Redis session management, React frontend, GPT-4 integration, custom prompting pipelines, and multi-source data connectors, built as a unified, tested system.
- Scale — The modular architecture and clean API layer ensure that new data sources, additional domain agents, and expanded research capabilities can be added as the institute’s needs grow, without re-engineering what is already working.
The Results
Over 70% Reduction in Manual Research Time. Richer Outputs. Scientists Back Doing Science.
CalibrBV launched as a production platform serving active biomedical research teams at Scripps Research. The outcomes were concrete.
- 70%+ reduction in manual data collection and synthesis time. The hours researchers previously spent navigating APIs, querying spreadsheets, and stitching findings together were absorbed by the agent network. The time savings were not marginal. They were structural.
- Richer, citation-backed reports. Multi-source reasoning produced research outputs with scientific traceability that manually assembled summaries rarely achieved. Every claim sourced. Every finding auditable.
- Researchers redirected to interpretation and innovation. The platform’s core productivity shift was not speed. It was reallocation. When data gathering is automated, researchers spend their time on the work that requires human expertise: hypothesis generation, experimental design, and scientific judgment.
- Scalable, extensible architecture. The modular agent design means adding a new data source, whether a new API or a new internal dataset, means adding or extending an agent rather than re-engineering the system. The platform can grow to accommodate additional sources without architectural disruption.
- Consistent, comparable outputs across the research team. Because every query runs through the same orchestrated agent pipeline with the same synthesis logic, reports are structurally consistent. Researchers working on adjacent questions produce outputs that are genuinely comparable, which matters for institutional research quality at the scale Scripps Research operates.
Why the Agentic Architecture Was the Right Choice
A conventional AI assistant connected to a few APIs might have automated part of this workflow. The retrieval part, perhaps. Or the summarization. Not both, reliably, across multiple heterogeneous data sources, with source traceability at the claim level.
The multi-agent architecture solved the problem that a single-model approach could not. The data landscape CalibrBV needed to navigate is not uniform. GlobalData APIs, Citeline spreadsheets, and public web sources each require different retrieval logic, different parsing strategies, and different quality standards for what counts as a usable output. Specialized agents handle each source on its own terms, and the Supervisor and Synthesis Agent bring those outputs into coherence.
That decomposition is also what makes the platform trustworthy. When each agent owns a discrete, testable scope, the system’s behavior is auditable at every stage. When a report’s claim is questioned, the trace runs back through synthesis, through retrieval, to the source. That chain of accountability is built into the architecture, not reconstructed after the fact.
Build Your AI Product with Aegasis Labs
CalibrBV is the kind of problem Aegasis Labs is built for: a domain with deep expertise requirements, a data landscape that defies simple automation, and end users whose time is too valuable to spend on information retrieval.
The multi-agent architecture did not just automate the workflow. It made the workflow trustworthy, scalable, and genuinely useful for scientists doing serious work at an institute with the scientific weight and history of Scripps Research.
Aegasis Labs has delivered 70+ projects across 8+ industries, including healthcare, biotechnology, and enterprise SaaS, with a 97% project completion success rate and 95% client satisfaction. Our 30+ consultants bring top 1% technical expertise across AI architecture, multi-agent systems, and cloud engineering. We are a certified partner of both AWS and Microsoft.
If your research or operations team is spending too much time gathering data and not enough time acting on it, we would like to show you what intelligent automation can do.